
23. 实现 GPT 分词器#
23.1. 介绍#
在预训练大语言模型时,模型需要逐词处理文本。通过下一词预测任务,我们可以训练参数量达数百万乃至数十亿的大模型,使其具备强大的语言理解与生成能力。这些模型经过进一步的微调,便可遵循通用指令或执行特定的目标任务。然而,在着手实现和训练大语言模型之前,我们首先需要准备好用于训练的数据集。
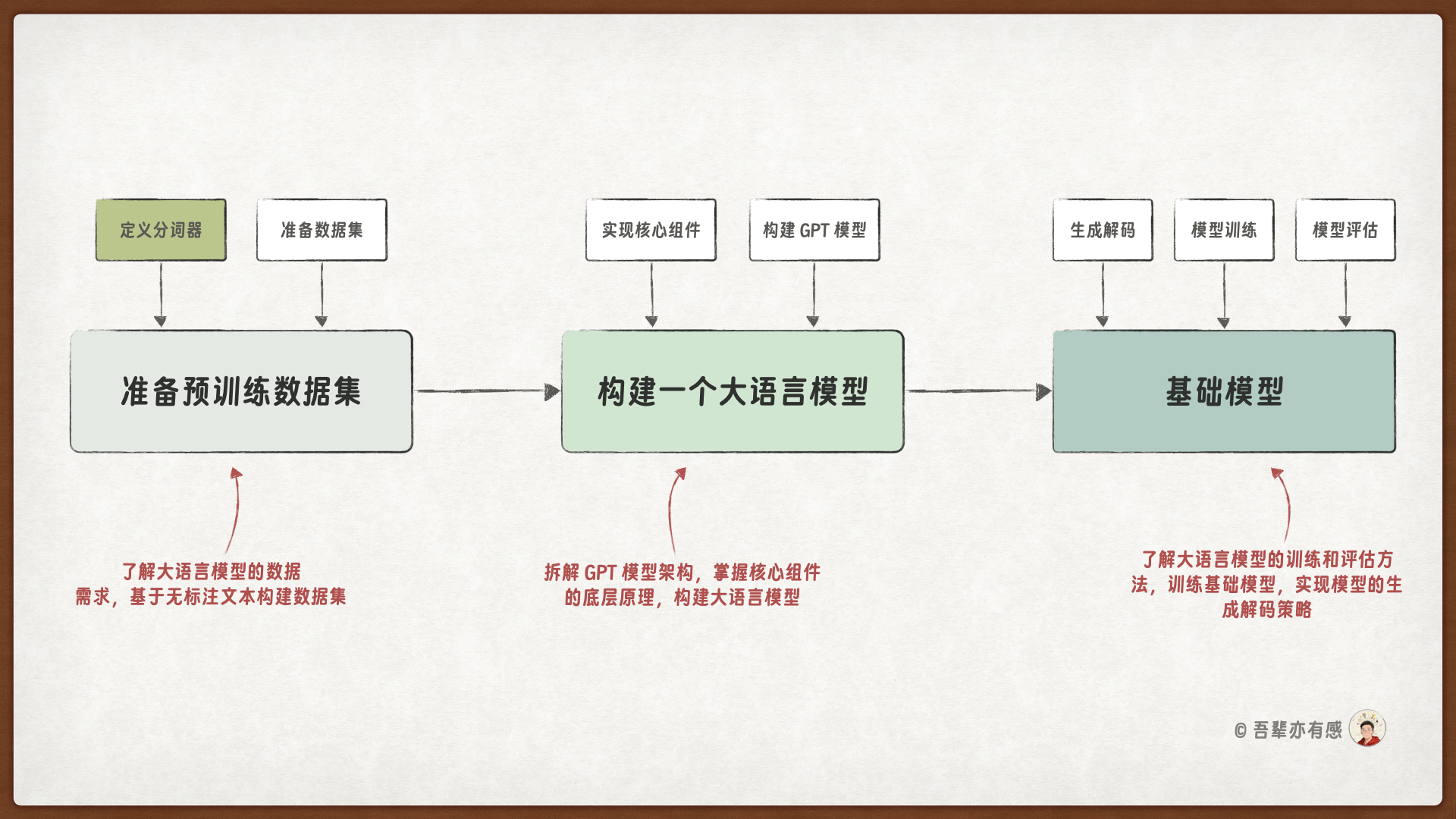
本节将带你学习如何通过分词器实现 GPT 的编码和解码过程,为训练大语言模型做好数据准备。具体包括:将文本切分为独立的单词词元和子词词元,将这些词元转换为模型能够处理的数值表示,以及将模型输出的预测结果重新还原为可读的文本。
23.2. 分词器在 GPT 中的作用#
分词器(Tokenizer)是连接人类语言与机器模型之间的桥梁,其核心功能可以概括为以下两个方面:
编码(Encoding):将连续的原始文本切分为离散的语义单元(Token),并将这些单元映射为对应的数字编号。这一过程使原本不可计算的文本转化为模型能够处理的结构化输入。
解码(Decoding):将模型输出的词元编号序列还原为自然语言文本,使得生成结果可以被人类理解和使用。
GPT 模型的文本生成过程,本质上是一个“编码—处理—解码”的循环:
编码阶段:分词器将用户输入的文本拆解并转换为词元 ID 序列,为模型提供数值化的输入。
处理阶段:模型以这些 ID 为输入进行前向计算,输出一个 logits 向量(即下一个词元的概率分布),用于预测下一个最可能的词元。
解码阶段:将模型选定的最高概率词元 ID 交还给分词器,由分词器将其还原为可读的文字,完成一次完整的生成步。
本节将带领你亲手实现编码与解码的流程,为后续构建 GPT 模型奠定基础。
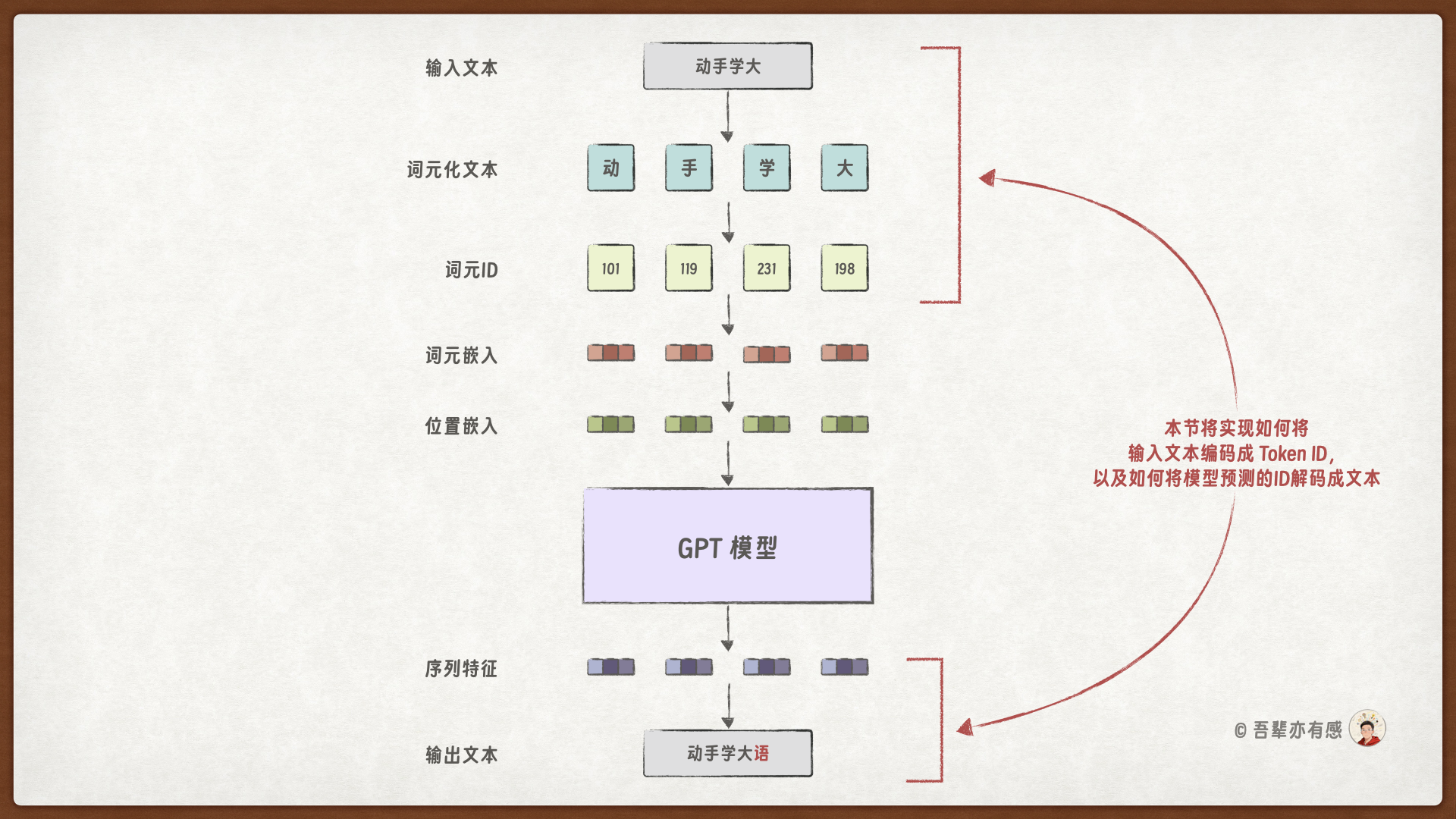
23.3. GPT 中的分词方法#
将输入文本分割为独立的词元(Token)是生成嵌入向量的必要预处理步骤,也是大语言模型理解语言的基础。词元可以是单个单词,也可以是标点符号等特殊字符。然而,GPT 模型采用的并非传统的单词分词,而是一种基于字节对编码(Byte Pair Encoding,BPE)的分词方法。BPE 属于子词分词(Subword Tokenization)技术,它通过将单词进一步拆分为更小的语义单元或字符组合,从而在词表规模与生僻词处理能力之间取得平衡。
以句子 动手学大语言模型 Hands-on Large Language Models 为例,使用 GPT 分词器得到的分词结果如下图所示:
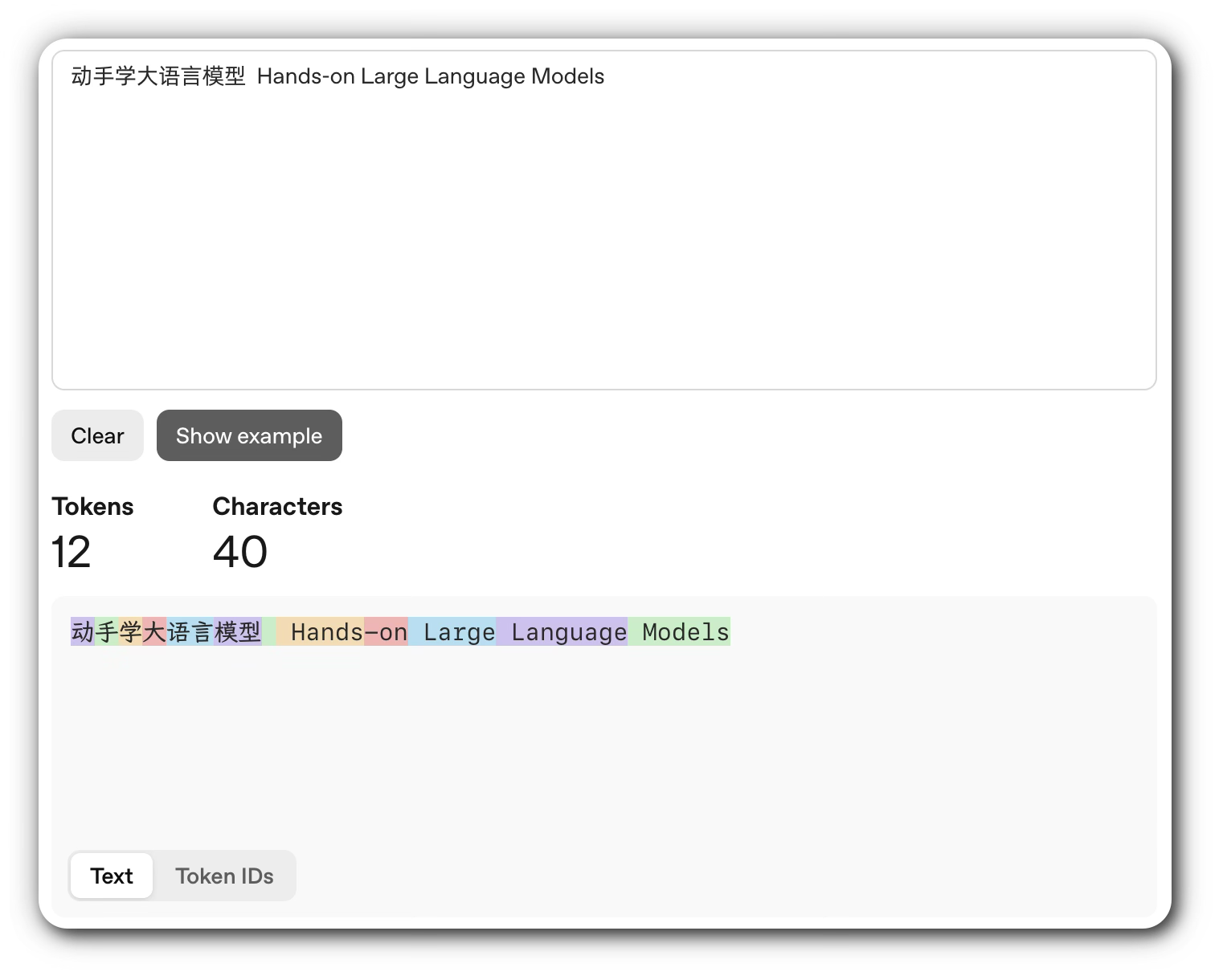
从结果中可以看到,GPT 分词器会将某些常用单词(如 Hands-on)分解为更小的子词单元。这种分解方式允许模型利用相同的词根来表征不同单词,从而有效处理未登录词(OOV)问题,并在多语言场景及词形变化丰富的语境中表现更佳。GPT 之所以选择 BPE 而非传统的单词级分词,正是为了在控制词表大小的同时,保持对罕见或新异词汇的建模能力。
接下来,我们将动手实现 GPT 的编码与解码方法。在开始之前,请确保已安装 dsxllm 库,并确认运行环境已准备就绪。
23.4. 环境配置#
23.4.1. 安装依赖#
!pip install --upgrade dsxllm
23.4.2. 环境版本#
from dsxllm.util import show_version
show_version()
本书愿景:
+------+--------------------------------------------------------+
| Info | 《动手学大语言模型》 |
+------+--------------------------------------------------------+
| 作者 | 吾辈亦有感 |
| 哔站 | https://space.bilibili.com/3546632320715420 |
| 定位 | 基于'从零构建'的理念,用实战帮助程序员快速入门大模型。 |
| 愿景 | 若让你的AI学习之路走的更容易一点,我将倍感荣幸!祝好😄 |
+------+--------------------------------------------------------+
环境信息:
+-------------+--------------+------------------------+
| Python 版本 | PyTorch 版本 | PyTorch Lightning 版本 |
+-------------+--------------+------------------------+
| 3.12.12 | 2.10.0 | 2.6.1 |
+-------------+--------------+------------------------+
23.5. 使用 Tiktoken 分词器#
Tiktoken 是由 OpenAI 开源的一款专为大语言模型设计的高性能分词器。其核心功能在于将自然语言文本高效地拆解为模型可识别的词元(Tokens)序列,这是所有 GPT 模型处理文本的必经环节。
该工具完整实现了字节对编码(BPE)算法,能够将文本无损地转换为数字序列,也能将模型输出的数字序列精准还原为原文。因此,我们可以直接复用这一成熟、高效的官方方案,无需自行构建分词器。
23.5.1. 定义编码和解码方法#
import torch
# 将文本编码为token ID序列,并转换为PyTorch张量
def text_to_token_ids(text, tokenizer):
# 使用指定的分词器将文本编码为token ID列表
encoded = tokenizer.encode(text, allowed_special={"<|endoftext|>"}) # 允许特殊字符
# 将token ID列表转换为PyTorch张量,并添加batch维度 (1, sequence_length)
encoded_tensor = torch.tensor(encoded).unsqueeze(0) # 添加 batch 维度
return encoded_tensor
# 将token ID张量解码为原始文本
def token_ids_to_text(token_ids, tokenizer):
# 移除batch维度,得到形状为(sequence_length,)的一维张量
flat = token_ids.squeeze(0) # 删除 batch 维度
# 将张量转换为Python列表,并使用分词器解码为文本
return tokenizer.decode(flat.tolist())
23.5.2. 测试编码和解码方法#
import tiktoken
from dsxllm.util import print_table
# 初始化 GPT-2 使用的分词器
tokenizer = tiktoken.get_encoding("gpt2")
# 示例文本
txt = "动手学 GPT"
# 将示例文本编码为token ID序列
token_ids = text_to_token_ids(txt, tokenizer)
# 打印分词结果表格
print_table(
"分词示例",
field_names=["Information", "Value"],
data=[
["原始文本", txt], # 显示原始文本
["编码结果", token_ids], # 显示编码后的token ID序列
[
"解码结果",
token_ids_to_text(token_ids, tokenizer),
], # 显示从token ID解码回的文本
],
)
分词示例:
+-------------+--------------------------------------------------------------------+
| Information | Value |
+-------------+--------------------------------------------------------------------+
| 原始文本 | 动手学 GPT |
| 编码结果 | tensor([[27950, 101, 33699, 233, 27764, 99, 402, 11571]]) |
| 解码结果 | 动手学 GPT |
+-------------+--------------------------------------------------------------------+
23.6. 答疑讨论#
○ 如果你觉得这篇文章有所帮助,欢迎将本文链接推荐给更多人——无论是分享到朋友圈、博客、社群,还是任何你常逛的地方。每一次转发,都会让它在搜索结果中更容易被有需要的人看到。